|
|
| Linia 260: |
Linia 260: |
| | | | |
| | * Complexitate în '''timp''': O(MAX_HASH) | | * Complexitate în '''timp''': O(MAX_HASH) |
| − | * Complexitate în '''spațiu''': O(1)
| |
| − |
| |
| − | = Exerciții =
| |
| − |
| |
| − |
| |
| − |
| |
| − | == Săptămâna 1 ==
| |
| − |
| |
| − | <ol>
| |
| − | <li> Dându-se header-ele <code>treeMap.h</code> și <code>server.h</code> de mai jos, implementați toate funcțiile definite în două fișiere sursă numite <code>server.c</code> și <code>treeMap.c</code>:
| |
| − | <ul><li> <code>server.h</code>:
| |
| − | <syntaxhighlight lang="C">
| |
| − | #ifndef SERVER_H
| |
| − | #define SERVER_H
| |
| − |
| |
| − | struct Server {
| |
| − | /* Numele server-ului in retea - sir de caractere */
| |
| − | char hostname[30];
| |
| − |
| |
| − | /* Adresa IP a server-ului o secvență de 4 valori numerice între 0 și 255 (ex: 192.168.1.10) */
| |
| − | unsigned char ipv4[4];
| |
| − |
| |
| − | /* Adresa hardware pentru adaptorul de retea - o secventa de 6 bytes, in hexa (ex: 60:57:18:6e:a8:e8). */
| |
| − | char hardwareAddress[6];
| |
| − |
| |
| − | /* Tipul procesorului - sir de caractere. */
| |
| − | char cpuType[10];
| |
| − |
| |
| − | /* Frecventa procesorului in Gigahertz. */
| |
| − | float cpuFrequencyGhz;
| |
| − |
| |
| − | /* Cantitatea de memorie RAM, in Gigabytes. */
| |
| − | float ramMemoryGigaBytes;
| |
| − |
| |
| − | /* Capacitatea discului, in Terabytes. */
| |
| − | float diskCapacityTeraBytes;
| |
| − | };
| |
| − |
| |
| − | /**
| |
| − | * Compara name1 cu name2 si intoarce o valoare corespunzătoare.
| |
| − | * @param name1 primul nume de comparat.
| |
| − | * @param name2 al doilea nume de comparat.
| |
| − | * @return o valoare pozitivă dacă primul nume este mai mare, o
| |
| − | * valoare negativă dacă al doilea nume este mai mare și 0 dacă
| |
| − | * numele sunt egale.
| |
| − | */
| |
| − | int compare(char * name1, char * name2);
| |
| − |
| |
| − | #endif
| |
| − | </syntaxhighlight>
| |
| − | </li>
| |
| − | <li> <code>treeMap.h</code>:
| |
| − | <syntaxhighlight lang="C">
| |
| − | #ifndef TREE_MAP_H
| |
| − | #define TREE_MAP_H
| |
| − |
| |
| − | #include "server.h"
| |
| − |
| |
| − | struct Pair {
| |
| − | char * key;
| |
| − | struct Server value;
| |
| − | };
| |
| − |
| |
| − | struct TreeNode {
| |
| − | struct TreeNode * parent;
| |
| − | struct TreeNode * left;
| |
| − | struct TreeNode * right;
| |
| − | struct Pair pair;
| |
| − | };
| |
| − |
| |
| − | struct TreeMap {
| |
| − | struct TreeNode * root;
| |
| − | unsigned size;
| |
| − | };
| |
| − |
| |
| − | /**
| |
| − | * Functia aloca memorie si intoarce un pointer la un nou TreeMap.
| |
| − | * @return adresa noului TreeMap.
| |
| − | */
| |
| − | struct TreeMap * createTreeMap();
| |
| − |
| |
| − | /**
| |
| − | * Functia intoarce numarul de elemente din map.
| |
| − | * @param map map-ul pentru care se cere dimensiunea.
| |
| − | * @return numarul de elemente din map.
| |
| − | */
| |
| − | unsigned treeMapSize(struct TreeMap * map);
| |
| − |
| |
| − | /**
| |
| − | * Functia intoarce 1 dacă map-ul nu conține nici un element.
| |
| − | * @param map map-ul de interes.
| |
| − | * @return 1 dacă map-ul este gol, 0 în rest.
| |
| − | */
| |
| − | char treeMapIsEmpty(struct TreeMap * map);
| |
| − |
| |
| − | /**
| |
| − | * Functia adauga elementul dat in map. Daca
| |
| − | * cheia exista deja, perechea existenta este suprascrisa.
| |
| − | * @param map map-ul in care trebuie adaugat elementul.
| |
| − | * @param key cheia din map (numele server-ului)
| |
| − | * @param value server-ul ce trebuie adaugat.
| |
| − | */
| |
| − | void treeMapPut(struct TreeMap * map, char * key, struct Server value);
| |
| − |
| |
| − | /**
| |
| − | * Functia cauta cheia data în map.
| |
| − | * @param key cheia de cautat
| |
| − | * @return 1 daca cheia exista in map, 0 daca nu.
| |
| − | */
| |
| − | char treeMapHasKey(struct TreeMap * map, char * key);
| |
| − |
| |
| − | /**
| |
| − | * Functia cauta o valoarea dupa cheia data în map.
| |
| − | * @param key cheia de cautat
| |
| − | * @return valoarea asociată cheii sau o structura goala daca cheia nu exista in map.
| |
| − | */
| |
| − | struct Server treeMapGet(struct TreeMap * map, char * key);
| |
| − |
| |
| − | /**
| |
| − | * Functia elimina perechea cu cheia dată din map daca acesta exista. Daca
| |
| − | * nu exista, functia nu are nici un efect.
| |
| − | * @param map map-ul din care trebuie eliminat elementul.
| |
| − | * @param key cheia perechii ce trebuie eliminată.
| |
| − | */
| |
| − | void treeMapRemove(struct TreeMap * map, char * key);
| |
| − |
| |
| − | /**
| |
| − | * Functia sterge tree map-ul specificat.
| |
| − | * @param map tree map-ul ce trebuie sters.
| |
| − | */
| |
| − | void deleteTreeMap(struct TreeMap * map);
| |
| − |
| |
| − | #endif
| |
| − | </syntaxhighlight>
| |
| − | </li>
| |
| − | </ul>
| |
| − | </li>
| |
| − | <li> Scrieți o altă sursă <code>main.c</code> în care să definiți o funcție <code>struct Server readFromKeyboard()</code> și o altă funcție <code>main</code> care să citească informații legate de servere de la tastatură până când ''hostname''-ul introdus este egal cu "-". Scrieți apoi o buclă care să citească nume de la tastatură, să caute server-ul în map și dacă nu este să afișeze un mesaj iar dacă este, să afișeze informații despre el. Programul se încheie când se introduce din nou "-".</li>
| |
| − | </ol>
| |
| − |
| |
| − |
| |
| − | == Săptămâna 2 ==
| |
| − |
| |
| − | <ol>
| |
| − | <li> Dându-se fișierele [[Fișier:hashMapLinkedList.h]], [[Fișier:hashMapLinkedList.c]] și header-ele <code>hashMap.h</code> și <code>person.h</code> de mai jos, implementați toate funcțiile definite în două fișiere sursă numite <code>person.c</code> și <code>hashMap.c</code>:
| |
| − | <ul><li> <code>person.h</code>:
| |
| − | <syntaxhighlight lang="C">
| |
| − | #ifndef PERSON_H
| |
| − | #define PERSON_H
| |
| − |
| |
| − | struct Person {
| |
| − | char firstName[30];
| |
| − | char lastName[30];
| |
| − | char idNumber[9]; // seria si numarul de buletin
| |
| − | char address[255];
| |
| − | char birthday[11];
| |
| − | char cnp[14];
| |
| − | };
| |
| − |
| |
| − | struct Pair {
| |
| − | char * key;
| |
| − | struct Person value;
| |
| − | };
| |
| − |
| |
| − | /**
| |
| − | * Functia intoarce 1 daca CNP-urile celor doua persoane sunt egale.
| |
| − | * @param cnp1 primul CNP de comparat.
| |
| − | * @param cnp2 al doilea CNP de comparat.
| |
| − | * @return 1 daca CNP-urile celor doua persoane sunt identice.
| |
| − | */
| |
| − | char equals(char * cnp1, char * cnp2);
| |
| − |
| |
| − | /**
| |
| − | * Functie hash pentru un CNP stocat ca string.
| |
| − | * @param cnp CNP-ul pentru care se doreste codul hash.
| |
| − | * @return codul hash al CNP-ului.
| |
| − | */
| |
| − | unsigned hash(char * cnp);
| |
| − |
| |
| − | #endif
| |
| − | </syntaxhighlight>
| |
| − | </li>
| |
| − | <li> <code>hashMap.h</code>:
| |
| − | <syntaxhighlight lang="C">
| |
| − | #ifndef HASH_MAP_H
| |
| − | #define HASH_MAP_H
| |
| − |
| |
| − | #include "hashMapLinkedList.h"
| |
| − | #include "person.h"
| |
| − |
| |
| − | #define MAX_HASH 1000000
| |
| − | struct HashMap {
| |
| − | struct LinkedList array[MAX_HASH]; // un vector de liste, una pentru fiecare valoare posibila de hash
| |
| − | unsigned size; // numarul de elemente din map
| |
| − | };
| |
| − |
| |
| − | /**
| |
| − | * Functia creeaza un hashMap nou si intoarce adresa de memorie alocata.
| |
| − | * @return un pointer la o structura de tip HashMap.
| |
| − | */
| |
| − | struct HashMap * createHashMap();
| |
| − |
| |
| − | /**
| |
| − | * Functia intoarce numarul de elemente din map.
| |
| − | * @param map map-ul pentru care se cere dimensiunea.
| |
| − | * @return numarul de elemente din map.
| |
| − | */
| |
| − | unsigned hashMapSize(struct HashMap * map);
| |
| − |
| |
| − | /**
| |
| − | * Functia intoarce 1 dacă map-ul nu conține nici un element.
| |
| − | * @param map map-ul de interes.
| |
| − | * @return 1 dacă map-ul este gol, 0 în rest.
| |
| − | */
| |
| − | char hashMapIsEmpty(struct HashMap * map);
| |
| − |
| |
| − | /**
| |
| − | * Functia adauga perechea data in map daca cheia nu exista. Daca
| |
| − | * cheia exista deja, valoarea si cheia sunt actualizate.
| |
| − | * @param map map-ul in care trebuie adaugata perechea.
| |
| − | * @param key cnp-ul folosit pe post de cheie.
| |
| − | * @param value persoana asociata CNP-ului.
| |
| − | */
| |
| − | void hashMapPut(struct HashMap * map, char * key, struct Person value);
| |
| − |
| |
| − | /**
| |
| − | * Functia elimina cheia data din map daca acesta exista. Daca
| |
| − | * nu exista, functia nu are nici un efect.
| |
| − | * @param map map-ul din care trebuie eliminat elementul.
| |
| − | * @param key cheia (CNP-ul) ce trebuie eliminata.
| |
| − | */
| |
| − | void hashMapRemove(struct HashMap * map, char * key);
| |
| − |
| |
| − | /**
| |
| − | * Functia intoarce 1 daca cheia specificata exista in map.
| |
| − | * @param map map-ul in care se cauta cheia.
| |
| − | * @param key cheia (CNP-ul) cautata.
| |
| − | * @return 1 daca cheia exista in map, 0 daca nu.
| |
| − | */
| |
| − | char hashMapHasKey(struct HashMap * map, char * key);
| |
| − |
| |
| − | /**
| |
| − | * Functia intoarce valoarea asociată cheii key.
| |
| − | * @param map map-ul in care se cauta cheia.
| |
| − | * @param key cheia (CNP-ul) cautata.
| |
| − | * @return valoarea asociată cheii.
| |
| − | */
| |
| − | struct Person hashMapGet(struct HashMap * map, char * key);
| |
| − |
| |
| − | /**
| |
| − | * Functia sterge hash map-ul specificat.
| |
| − | * @param map hash map-ul ce trebuie sters.
| |
| − | */
| |
| − | void deleteHashMap(struct HashMap * map);
| |
| − |
| |
| − | #endif
| |
| − | </syntaxhighlight>
| |
| − | </li>
| |
| − | </ul>
| |
| − | </li>
| |
| − | <li> Scrieți o altă sursă <code>main.c</code> în care să definiți o funcție <code>struct Person readFromKeyboard()</code> și o altă funcție <code>main</code> care să citească persoane de la tastatură până când numele introdus este egal cu "-". Se citesc apoi CNP-uri până la introducerea din nou a caracterului "-", și pentru fiecare CNP introdus se afișează imediat datele persoanei sau textul "Persoana inexistenta".</li>
| |
| − | </ol>
| |
| − |
| |
| − |
| |
| − | == Implementarea map-urilor cu arbori binari de căutare (Binary Search Trees - BST) ==
| |
| − |
| |
| − | Pentru a putea plasa elemente într-un map implementat cu arbori binari de căutare, pe mulțimea cheilor
| |
| − | trebuie să existe definită o relație de ordine.
| |
| − |
| |
| − | Map-urile implementate cu arbori binari de căutare, în plus față proprietățile map-urilor definite mai sus, garantează
| |
| − | faptul că elementele sunt plasate în ordinea cheilor în structură (Ordered Map).
| |
| − |
| |
| − | Din acest motiv trebuie definită o funcție care să compare două chei. Vom numi această funcție <code>compare</code> și se ca comporta similar cu funcția <code>strcmp</code>: va întoarce o valoare pozitivă dacă primul element e mai mare, o valoare negativă dacă al doilea element e mai mare și 0 dacă elementele sunt egale:
| |
| − |
| |
| − | <syntaxhighlight lang="c">
| |
| − | /**
| |
| − | * Compara value1 cu value2 si intoarce o valoare corespunzătoare.
| |
| − | * @param value1 prima valoare de comparat.
| |
| − | * @param value2 a doua valoare de comparat.
| |
| − | * @return o valoare pozitivă dacă primul element e mai mare, o
| |
| − | * valoare negativă dacă al doilea element e mai mare și 0 dacă
| |
| − | * elementele sunt egale.
| |
| − | */
| |
| − | int compare(K value1, K value2);
| |
| − | </syntaxhighlight>
| |
| − |
| |
| − | === Tipul de date și funcțiile de bază ===
| |
| − |
| |
| − | În continuare vom prezenta un exemplu de map pentru elemente de tip "server" implementată cu arbori binari de căutare. În primul rând vom defini structura ce memorează datele legate de un server:
| |
| − | <syntaxhighlight lang="c">
| |
| − | struct Server {
| |
| − | /* Numele server-ului in retea - sir de caractere */
| |
| − | char hostname[30];
| |
| − |
| |
| − | /* Adresa IP a server-ului o secvență de 4 valori numerice între 0 și 255 (ex: 192.168.1.10) */
| |
| − | unsigned char ipv4[4];
| |
| − |
| |
| − | /* Adresa hardware pentru adaptorul de retea - o secventa de 6 bytes, in hexa (ex: 60:57:18:6e:a8:e8). */
| |
| − | char hardwareAddress[6];
| |
| − |
| |
| − | /* Tipul procesorului - sir de caractere. */
| |
| − | char cpuType[10];
| |
| − |
| |
| − | /* Frecventa procesorului in Gigahertz. */
| |
| − | float cpuFrequencyGhz;
| |
| − |
| |
| − | /* Cantitatea de memorie RAM, in Gigabytes. */
| |
| − | float ramMemoryGigaBytes;
| |
| − |
| |
| − | /* Capacitatea discului, in Terabytes. */
| |
| − | float diskCapacityTeraBytes;
| |
| − | };
| |
| − | </syntaxhighlight>
| |
| − |
| |
| − | Vom folosi pe post de cheie în map hostname-ul server-ului, prin urmare definim:
| |
| − | * tipul de date al cheii este '''char *''';
| |
| − | * tipul de date al valorii este '''struct Server''';
| |
| − |
| |
| − | Pentru a implementa un map de servere folosind BST, avem întâi nevoie să definim funcția de comparare a două chei:
| |
| − | <syntaxhighlight lang="c">
| |
| − | /**
| |
| − | * Compara name1 cu name2 si intoarce o valoare corespunzătoare.
| |
| − | * @param name1 primul nume de comparat.
| |
| − | * @param name2 al doilea nume de comparat.
| |
| − | * @return o valoare pozitivă dacă primul nume este mai mare, o
| |
| − | * valoare negativă dacă al doilea nume este mai mare și 0 dacă
| |
| − | * numele sunt egale.
| |
| − | */
| |
| − | int compare(char * name1, char * name2);
| |
| − | </syntaxhighlight>
| |
| − |
| |
| − | === Structurile <code>TreeMap</code>, <code>TreeNode</code> și <code>Pair</code> ===
| |
| − |
| |
| − | Pentru stocarea datelor necesare pentru map, definim următoarele structuri:
| |
| − |
| |
| − | <syntaxhighlight lang="C">
| |
| − | struct Pair {
| |
| − | char * key;
| |
| − | struct Server value;
| |
| − | };
| |
| − |
| |
| − | struct TreeNode {
| |
| − | struct TreeNode * parent;
| |
| − | struct TreeNode * left;
| |
| − | struct TreeNode * right;
| |
| − | struct Pair pair;
| |
| − | };
| |
| − |
| |
| − | struct TreeMap {
| |
| − | struct TreeNode * root;
| |
| − | unsigned size;
| |
| − | };
| |
| − | </syntaxhighlight>
| |
| − |
| |
| − | === Crearea unui <code>TreeMap</code> ===
| |
| − |
| |
| − | Pentru a crea un <code>TreeMap</code>, definim următoarea funcție:
| |
| − |
| |
| − | <syntaxhighlight lang="C">
| |
| − | /**
| |
| − | * Functia aloca memorie si intoarce un pointer la un nou TreeMap.
| |
| − | * @return adresa noului TreeMap.
| |
| − | */
| |
| − | struct TreeMap * createTreeMap();
| |
| − | </syntaxhighlight>
| |
| − |
| |
| − | Funcția trebuie să realizeze următorii pași:
| |
| − | # Se alocă memorie pentru un nou <code>struct TreeMap</code> ce trebuie inițializată automat cu 0.
| |
| − | # Se întoarce adresa alocată.
| |
| − |
| |
| − | * Complexitate în '''timp''': O(1)
| |
| − | * Complexitate în '''spațiu''': O(1)
| |
| − |
| |
| − | === Interogarea numărului de elemente din map ===
| |
| − |
| |
| − | Pentru interogarea numărului de elemente din map definim:
| |
| − |
| |
| − | <syntaxhighlight lang="C">
| |
| − | /**
| |
| − | * Functia intoarce numarul de elemente din map.
| |
| − | * @param map map-ul pentru care se cere dimensiunea.
| |
| − | * @return numarul de elemente din map.
| |
| − | */
| |
| − | unsigned treeMapSize(struct TreeMap * map);
| |
| − | </syntaxhighlight>
| |
| − |
| |
| − | Funcția va întoarce valoarea din câmpul <code>size</code> din structură.
| |
| − |
| |
| − | * Complexitate în '''timp''': O(1)
| |
| − | * Complexitate în '''spațiu''': O(1)
| |
| − |
| |
| − | Pentru a afla dacă map-ul este gol definim:
| |
| − |
| |
| − | <syntaxhighlight lang="C">
| |
| − | /**
| |
| − | * Functia intoarce 1 dacă map-ul nu conține nici un element.
| |
| − | * @param map map-ul de interes.
| |
| − | * @return 1 dacă map-ul este gol, 0 în rest.
| |
| − | */
| |
| − | char treeMapIsEmpty(struct TreeMap * map);
| |
| − | </syntaxhighlight>
| |
| − |
| |
| − | Funcția va întoarce 1 dacă valoarea din câmpul <code>size</code> este 0.
| |
| − |
| |
| − | * Complexitate în '''timp''': O(1)
| |
| − | * Complexitate în '''spațiu''': O(1)
| |
| − |
| |
| − | === Adăugarea unui element în map ===
| |
| − |
| |
| − | Pentru operația de adăugare se definește următoarea funcție:
| |
| − |
| |
| − | <syntaxhighlight lang="C">
| |
| − | /**
| |
| − | * Functia adauga elementul dat in map. Daca
| |
| − | * cheia exista deja, perechea existenta este suprascrisa.
| |
| − | * @param map map-ul in care trebuie adaugat elementul.
| |
| − | * @param key cheia din map (numele server-ului)
| |
| − | * @param value server-ul ce trebuie adaugat.
| |
| − | */
| |
| − | void treeMapPut(struct TreeMap * map, char * key, struct Server value);
| |
| − | </syntaxhighlight>
| |
| − |
| |
| − | Adăugarea se realizează în felul următor:
| |
| − | # Dacă dimensiunea map-ului este 0, se alocă memorie pentru un nod nou <code>newNode</code> în care:
| |
| − | #* <code>pair.key</code> va lua valoarea lui <code>key</code>
| |
| − | #* <code>pair.value</code> va lua valoarea lui <code>value</code>
| |
| − | #* <code>parent</code>, <code>left</code> și <code>right</code> vor lua valoarea <code>NULL</code>.
| |
| − | # Câmpul <code>root</code> ia valoarea <code>newNode</code>, <code>size</code> se incrementează și funcția se încheie.
| |
| − | # Altfel, se definește o variabilă de tip nod numită <code>tmpNode</code> care se inițializează cu valoarea câmpului <code>root</code>.
| |
| − | # Într-o buclă infinită se realizează următorii pași:
| |
| − | ## Dacă rezultatul funcției <code>compare</code> cu argumentele <code>tmpNode->pair.key</code> și <code>key</code> este 0 (elementele sunt egale), <code>tmpNode->pair.key</code> ia valoarea <code>key</code>, <code>tmpNode->pair.value</code> ia valoarea <code>value</code> și funcția se încheie.
| |
| − | ## Dacă rezultatul funcției <code>compare</code> cu argumentele <code>tmpNode->pair.key</code> și <code>key</code> este mai mare ca 0 și <code>tmpNode->left</code> este diferit de <code>NULL</code>, atunci <code>tmpNode</code> ia valoarea <code>tmpNode->left</code>.
| |
| − | ## Dacă rezultatul funcției <code>compare</code> cu argumentele <code>tmpNode->pair.key</code> și <code>key</code> este mai mare ca 0 și <code>tmpNode->left</code> este egal cu <code>NULL</code>, atunci se alocă memorie pentru un nod <code>newNode</code> nou după regula de la 1, <code>newNode->parent</code> ia valoarea lui <code>tmpNode</code>, <code>tmpNode->left</code> ia valoarea lui <code>newNode</code>, <code>size</code> se incrementează cu 1 și funcția se încheie.
| |
| − | ## Dacă rezultatul funcției <code>compare</code> cu argumentele <code>tmpNode->pair.key</code> și <code>key</code> este mai mică ca 0 și <code>tmpNode->right</code> este diferit de <code>NULL</code>, atunci <code>tmpNode</code> ia valoarea <code>tmpNode->right</code>.
| |
| − | ## Dacă rezultatul funcției <code>compare</code> cu argumentele <code>tmpNode->pair.key</code> și <code>key</code> este mai mică ca 0 și <code>tmpNode->right</code> este egal cu <code>NULL</code>, atunci se alocă memorie pentru un nod <code>newNode</code> nou după regula de la 1, <code>newNode->parent</code> ia valoarea lui <code>tmpNode</code>, <code>tmpNode->right</code> ia valoarea lui <code>newNode</code>, <code>size</code> se incrementează cu 1 și funcția se încheie.
| |
| − |
| |
| − | * Complexitate în '''timp''': O(1) best case (element adăugat imediat sub rădăcină), O(log<sub>2</sub>n) average case (arbore echilibrat), O(n) worst case (arbore dezechilibrat).
| |
| − | * Complexitate în '''spațiu''': O(1)
| |
| − |
| |
| − | === Verificarea dacă o cheie există în map ===
| |
| − |
| |
| − | Pentru operația de căutare a unei chei se definește următoarea funcție:
| |
| − |
| |
| − | <syntaxhighlight lang="C">
| |
| − | /**
| |
| − | * Functia cauta cheia data în map.
| |
| − | * @param key cheia de cautat
| |
| − | * @return 1 daca cheia exista in map, 0 daca nu.
| |
| − | */
| |
| − | char treeMapHasKey(struct TreeMap * map, char * key);
| |
| − | </syntaxhighlight>
| |
| − |
| |
| − | Căutarea unei chei într-un map se realizează în felul următor:
| |
| − | # Se definește un pointer la nod numit <code>tmpNode</code> care se inițializează cu valoarea lui <code>root</code>.
| |
| − | # Cât timp <code>tmpNode</code> este diferit de <code>NULL</code>:
| |
| − | #* Dacă rezultatul funcției <code>compare</code> cu argumentele <code>tmpNode->pair.key</code> și <code>key</code> este 0, se întoarce valoarea 1 (elementul a fost găsit).
| |
| − | #* Dacă rezultatul funcției <code>compare</code> cu argumentele <code>tmpNode->pair.key</code> și <code>key</code> este pozitiv, <code>tmpNode</code> ia valoarea lui <code>tmpNode->left</code>.
| |
| − | #* Dacă rezultatul funcției <code>compare</code> cu argumentele <code>tmpNode->pair.key</code> și <code>key</code> este negativ, <code>tmpNode</code> ia valoarea lui <code>tmpNode->right</code>.
| |
| − | # Când s-a ieșit din buclă, se întoarce 0 (elementul nu a fost găsit).
| |
| − |
| |
| − | * Complexitate în '''timp''': O(1) best case (element găsit în rădăcină), O(log<sub>2</sub>n) average case (arbore echilibrat), O(n) worst case (arbore dezechilibrat).
| |
| − | * Complexitate în '''spațiu''': O(1)
| |
| − |
| |
| − | === Căutarea unei valori după o cheie dată ===
| |
| − |
| |
| − | Pentru operația de căutare a unei valori după o cheie dată se definește următoarea funcție:
| |
| − |
| |
| − | <syntaxhighlight lang="C">
| |
| − | /**
| |
| − | * Functia cauta o valoarea dupa cheia data în map.
| |
| − | * @param key cheia de cautat
| |
| − | * @return valoarea asociată cheii sau o structura goala daca cheia nu exista in map.
| |
| − | */
| |
| − | struct Server treeMapGet(struct TreeMap * map, char * key);
| |
| − | </syntaxhighlight>
| |
| − |
| |
| − | Căutarea unei valori după o cheie într-un map se realizează în felul următor:
| |
| − | # Se definește un pointer la nod numit <code>tmpNode</code> care se inițializează cu valoarea lui <code>root</code>.
| |
| − | # Cât timp <code>tmpNode</code> este diferit de <code>NULL</code>:
| |
| − | #* Dacă rezultatul funcției <code>compare</code> cu argumentele <code>tmpNode->pair.key</code> și <code>key</code> este 0, se întoarce <code>tmpNode->pair.value</code> (elementul a fost găsit).
| |
| − | #* Dacă rezultatul funcției <code>compare</code> cu argumentele <code>tmpNode->pair.key</code> și <code>key</code> este pozitiv, <code>tmpNode</code> ia valoarea lui <code>tmpNode->left</code>.
| |
| − | #* Dacă rezultatul funcției <code>compare</code> cu argumentele <code>tmpNode->pair.key</code> și <code>key</code> este negativ, <code>tmpNode</code> ia valoarea lui <code>tmpNode->right</code>.
| |
| − | # Când s-a ieșit din buclă, se întoarce valoarea unei structuri de tip Server fără conținut (elementul nu a fost găsit).
| |
| − |
| |
| − | * Complexitate în '''timp''': O(1) best case (element găsit în rădăcină), O(log<sub>2</sub>n) average case (arbore echilibrat), O(n) worst case (arbore dezechilibrat).
| |
| − | * Complexitate în '''spațiu''': O(1)
| |
| − |
| |
| − | === Eliminarea unui element din map ===
| |
| − |
| |
| − | Pentru operația de eliminare se definește următoarea funcție:
| |
| − |
| |
| − | <syntaxhighlight lang="C">
| |
| − | /**
| |
| − | * Functia elimina perechea cu cheia dată din map daca acesta exista. Daca
| |
| − | * nu exista, functia nu are nici un efect.
| |
| − | * @param map map-ul din care trebuie eliminat elementul.
| |
| − | * @param key cheia perechii ce trebuie eliminată.
| |
| − | */
| |
| − | void treeMapRemove(struct TreeMap * map, char * key);
| |
| − | </syntaxhighlight>
| |
| − |
| |
| − | Eliminarea se realizează în felul următor (o descriere în imagini poate fi găsită [http://www.algolist.net/Data_structures/Binary_search_tree/Removal aici] - nu încercați să folosiți codul de pe acea pagină deoarece structurile din platformă diferă și în plus limbajul este C++ și nu va compila):
| |
| − | # Folosind un pointer la nod <code>tmpNode</code>, se folosește tehnica de la căutarea chei în map pentru a identifica nodul care memorează cheia <code>key</code>. Dacă funcția ajunge la frunze fără a găsi server-ul căutat, funcția se încheie (cheia nu există în map). Altfel, <code>tmpNode</code> va fi pointer la nodul ce trebuie eliminat. În plus, se va defini o variabilă de tip char <code>direction</code> care la fiecare avansare în arbore va lua valoarea -1 dacă avansarea s-a făcut spre stânga și 1 dacă s-a făcut spre dreapta, astfel încât atunci când <code>tmpNode</code> este pointer la nodul ce trebuie șters, <code>direction</code> va fi 1 sau -1 în funcție de poziția nodului <code>tmpNode</code> față de nodul părinte.
| |
| − | # Dacă <code>tmpNode->left</code> și <code>tmpNode->right</code> sunt ambele <code>NULL</code> (nodul ce trebuie șters este frunză), atunci, dacă <code>direction</code> este -1, <code>tmpNode->parent->left</code> ia valoarea <code>NULL</code>, altfel <code>tmpNode->parent->right</code> ia valoarea <code>NULL</code>, nodul <code>tmpNode</code> este dezalocat, <code>size</code> se decrementează și funcția se încheie.
| |
| − | # Dacă <code>tmpNode->left</code> este <code>NULL</code> și <code>tmpNode->right</code> este diferit de <code>NULL</code> (nodul are un singur copil), atunci, dacă <code>direction</code> este -1, <code>tmpNode->parent->left</code> ia valoarea <code>tmpNode->right</code>, altfel <code>tmpNode->parent->right</code> ia valoarea <code>tmpNode->right</code>, nodul <code>tmpNode</code> este dezalocat, <code>size</code> se decrementează și funcția se încheie.
| |
| − | # Dacă <code>tmpNode->left</code> este diferit de <code>NULL</code> și <code>tmpNode->right</code> este <code>NULL</code> (nodul are un singur copil), atunci, dacă <code>direction</code> este -1, <code>tmpNode->parent->left</code> ia valoarea <code>tmpNode->left</code>, altfel <code>tmpNode->parent->right</code> ia valoarea <code>tmpNode->left</code>, nodul <code>tmpNode</code> este dezalocat, <code>size</code> se decrementează și funcția se încheie.
| |
| − | # Dacă <code>tmpNode->left</code> și <code>tmpNode->right</code> sunt ambele diferite de <code>NULL</code> (nodul ce trebuie șters are doi copii), atunci:
| |
| − | #* Se foloște un al doilea pointer la nod numit <code>minSubtreeNode</code> cu care se caută cea mai mică cheie din subarborele din dreapta nodului <code>tmpNode</code>.
| |
| − | #* <code>tmpNode->pair</code> ia valoarea <code>minSubtreeNode->pair</code> apoi se șterge <code>minSubtreeNode</code> după aceleași reguli de mai sus.
| |
| − |
| |
| − | * Complexitate în '''timp''': O(1) best case (element găsit imediat sub rădăcină), O(log<sub>2</sub>n) average case (arbore echilibrat), O(n) worst case (arbore dezechilibrat).
| |
| − | * Complexitate în '''spațiu''': O(1)
| |
| − |
| |
| − | === Ștergerea unui <code>TreeMap</code>===
| |
| − |
| |
| − | Pentru dezalocarea unui <code>TreeMap</code>, se definește următoarea funcție:
| |
| − | <syntaxhighlight lang="C">
| |
| − | /**
| |
| − | * Functia sterge tree map-ul specificat.
| |
| − | * @param map tree map-ul ce trebuie sters.
| |
| − | */
| |
| − | void deleteTreeMap(struct TreeMap * map);
| |
| − | </syntaxhighlight>
| |
| − |
| |
| − | Pentru ștergerea unui <code>TreeMap</code> se urmează următorii pași:
| |
| − | # Se realizează o parcurgere în post-ordine (stânga-dreapta-rădăcină) și se șterg toate nodurile din arbore.
| |
| − | # Se șterge memoria alocată pentru structura de tip <code>TreeMap</code>.
| |
| − |
| |
| − | * Complexitate în '''timp''': O(n)
| |
| | * Complexitate în '''spațiu''': O(1) | | * Complexitate în '''spațiu''': O(1) |
În acest laborator se vor implementa structuri de date asociative (map) cu arbori binari și funcții hash.
Structura de date asociativă - Map
Structura de date asociativă (map) este o structură de date abstractă care stochează perechi de elemente cheie-valoare,
într-o ordine arbitrară stabilită de structură, astfel încât nu pot exista două perechi cu aceeași cheie în map.
În esență, un map este o mulțime (set) de chei care sunt întotdeauna stocate împreună cu o valoare.
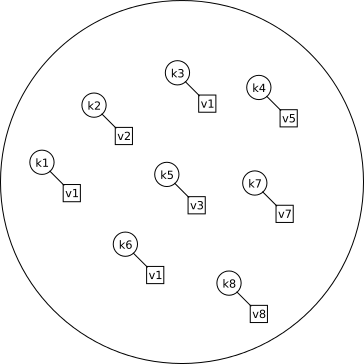
Map-ul are următoarele proprietăți:
- Datele sunt plasate într-o ordine oarecare stabilită arbitrar de structură.
- Numărul de elemente ce poate fi stocat de structură este nelimitat.
- Elementele stocate în map sunt de același fel.
- Tipul de date al cheii și tipul de date al valorii pot fi diferite.
- Map-ul poate conține doar chei unice, în baza unei funcții definite de egalitate. Altfel spus, dacă două chei sunt egale din punctul de vedere al map-ului, ele nu pot fi ambele prezente în perechi cheie-valoare în map.
Map-ul suportă următoarele operații de bază:
- Interogarea numărului de elemente din map.
- Verificarea dacă map-ul este gol.
- Adăugarea perechi cheie-valoare (insert) - dacă cheia există deja în map, aceasta nu se înlocuiește.
- Verificarea dacă o cheie există în map (count).
- Căutarea unei valori după o cheie dată (at);
- Eliminarea unei chei din map (erase).
Implementarea de structuri asociative cu funcții hash
Definirea funcțiilor hash și a proprietăților lor s-a făcut în laboratorul 5 (SDA Lucrarea 5#Implementarea de mulțimi cu funcții hash).
Tipul de date și funcțiile de bază
În continuare vom prezenta un exemplu de map de la CNP (cheia) la elemente de tip "persoană" (valoarea), implementată cu funcții hash. În primul rând vom defini structura ce memorează datele legate de o persoană:
struct Person {
char firstName[30];
char lastName[30];
char idNumber[9]; // seria si numarul de buletin
char address[255];
char birthday[11];
char cnp[14];
};
Pentru a implementa o funcție hash pentru variabilele de tip char * (cheia este CNP-ul care este stocat ca un șir de caractere), avem întâi nevoie să definim operația de egalitate:
/**
* Functia intoarce 1 daca CNP-urile celor doua persoane sunt egale.
* @param cnp1 primul CNP de comparat.
* @param cnp2 al doilea CNP de comparat.
* @return 1 daca CNP-urile celor doua persoane sunt identice.
*/
char equals(char * cnp1, char * cnp2);
Mai departe definim funcția hash pentru un CNP.
Pentru a putea implementa un map cu funcții hash trebuie ca hash-ul maxim să fie o valoare rezonabilă pentru a putea aloca memorie cu dimensiunea valorii respective.
Din motivul de mai sus, și pentru a micșora posibilitatea unei coliziuni de hash ce va micșora performanța structurii, ieșirea funcției hash va fi un număr între 0 și 999999 obținut din ultimele 6 cifre ale CNP-ului convertite din text în număr (pentru conversie puteți folosi funcția atoi):
/**
* Functie hash pentru un CNP stocat ca string.
* @param cnp CNP-ul pentru care se doreste codul hash.
* @return codul hash al CNP-ului.
*/
unsigned hash(char * cnp);
În continuare vom utiliza pentru implementarea unui Hash Map o structură de date de tip secvență împlementată cu liste (LinkedList) și vom folosi funcțiile deja definite de la laboratoarele anterioare:
Elementul stocat în listă este un element de tip Pair care stochează împreună o cheie cu o valoare:
struct Pair {
char * key; /* CNP-ul */
struct Person value; /* Persoana */
};
Structura HashMap
Pentru stocarea datelor necesare map-ului, definim următoarea structură:
#define MAX_HASH 1000000
struct HashMap {
struct LinkedList array[MAX_HASH]; // un vector de liste, una pentru fiecare valoare posibila de hash
unsigned size; // numarul de elemente din map
};
Crearea unui HashMap
Pentru crearea unui HashMap, se definește următoarea funcție:
/**
* Functia creeaza un hashMap nou si intoarce adresa de memorie alocata.
* @return un pointer la o structura de tip HashMap.
*/
struct HashMap * createHashMap();
Pentru crearea unui HashMap se urmează următorii pași:
- Se alocă memorie pentru un element de tip
struct HashMap folosind funcția corectă pentru reseta memoria la alocare (scrierea ei cu 0).
- Se inițializează
size cu 0.
- Se întoarce adresa elementului de tip
struct HashMap.
- Complexitate în timp: O(1)
- Complexitate în spațiu: O(MAX_HASH)
Interogarea numărului de elemente din map
Pentru interogarea numărului de elemente din map definim:
/**
* Functia intoarce numarul de elemente din map.
* @param map map-ul pentru care se cere dimensiunea.
* @return numarul de elemente din map.
*/
unsigned hashMapSize(struct HashMap * map);
Funcția va întoarce valoarea din câmpul size din structură.
- Complexitate în timp: O(1)
- Complexitate în spațiu: O(1)
Pentru a afla dacă map-ul este gol definim:
/**
* Functia intoarce 1 dacă map-ul nu conține nici un element.
* @param map map-ul de interes.
* @return 1 dacă map-ul este gol, 0 în rest.
*/
char hashMapIsEmpty(struct HashMap * map);
Funcția va întoarce 1 dacă valoarea din câmpul size este 0.
- Complexitate în timp: O(1)
- Complexitate în spațiu: O(1)
Adăugarea unei perechi cheie-valoare în map
Pentru operația de adăugare se definește următoarea funcție:
/**
* Functia adauga perechea data in map daca cheia nu exista. Daca
* cheia exista deja, valoarea si cheia sunt actualizate.
* @param map map-ul in care trebuie adaugata perechea.
* @param key cnp-ul folosit pe post de cheie.
* @param value persoana asociata CNP-ului.
*/
void hashMapPut(struct HashMap * map, char * key, struct Person value);
Adăugarea se realizează în felul următor:
- Se aplică funcția hash pe variabila
key.
- Folosind valoarea obținută se accesează lista de pe poziția hash-ului din
array.
- Se iterează peste nodurile listei căutând cheia
key în pereche, folosind funcția equals. Dacă cheia este găsită, atunci cheia și valoarea din pereche sunt actualizate cu valorile argumentelor key și value și funcția se încheie; altfel, se crează un nod nou care se adaugă listei care va conține perechea key - value, dimensiunea listei și dimensiunea map-ului se incrementează.
- Complexitate în timp: O(1) best case (fără coliziuni), O(1) average case pentru număr mai mic de 1000000 de persoane, O(n) worst case (același hash pentru poate persoanele).
- Complexitate în spațiu: O(1)
Atenție: Deoarece vectorul array conține variabile de tip struct LinkedList și nu pointeri, pentru a folosi funcțiile definite în hashMapLinkedList.h e necesară obținerea adresei variabilei de tip struct LinkedList folosind operatorul &.
Eliminarea unei chei din map
Pentru operația de eliminare se definește următoarea funcție:
/**
* Functia elimina cheia data din map daca acesta exista. Daca
* nu exista, functia nu are nici un efect.
* @param map map-ul din care trebuie eliminat elementul.
* @param key cheia (CNP-ul) ce trebuie eliminata.
*/
void hashMapRemove(struct HashMap * map, char * key);
Eliminarea se realizează în felul următor:
- Se aplică funcția hash pe variabila
key.
- Folosind valoarea obținută se accesează lista de pe poziția hash-ului din
array.
- Se folosește funcția
linkedListSearch pentru a verifica dacă person există în listă.
- Dacă valoarea întoarsă este diferită de -1 atunci se folosește funcția
linkedListDelete pentru a șterge elementul de pe poziția respectivă și size se decrementează cu 1.
- Complexitate în timp: O(1) best case (fără coliziuni), O(1) average case pentru număr mai mic de 1000000 de persoane, O(n) worst case (același hash pentru poate persoanele).
- Complexitate în spațiu: O(1)
Verificarea dacă o cheie există în map
Pentru a verifica dacă o cheie există în map, se definește următoarea funcție:
/**
* Functia intoarce 1 daca cheia specificata exista in map.
* @param map map-ul in care se cauta cheia.
* @param key cheia (CNP-ul) cautata.
* @return 1 daca cheia exista in map, 0 daca nu.
*/
char hashMapHasKey(struct HashMap * map, char * key);
Verificarea unei chei dacă este sau nu în map se realizează în felul următor:
- Se aplică funcția hash pe variabila
key.
- Folosind valoarea obținută se accesează lista de pe poziția hash-ului din
array.
- Se folosește funcția
linkedListSearch pentru a verifica dacă key există în listă.
- Dacă valoarea întoarsă este diferită de -1 atunci se întoarce 1, altfel se întoarce 0.
- Complexitate în timp: O(1) best case (fără coliziuni), O(1) average case pentru număr mai mic de 1000000 de persoane, O(n) worst case (același hash pentru poate persoanele).
- Complexitate în spațiu: O(1)
Căutarea unei valori după cheie
Pentru a căuta o valoare după cheie, se definește urmtoarea funcție:
/**
* Functia intoarce valoarea asociată cheii key.
* @param map map-ul in care se cauta cheia.
* @param key cheia (CNP-ul) cautata.
* @return valoarea asociată cheii.
*/
struct Person hashMapGet(struct HashMap * map, char * key);
Căutarea unei valori după cheie se realizează în felul următor:
- Se aplică funcția hash pe variabila
key.
- Folosind valoarea obținută se accesează lista de pe poziția hash-ului din
array.
- Se iterează peste nodurile din listă și se caută cheia folosind funcția
equals.
- Dacă cheia a fost găsită, se întoarce valoarea asociată; dacă s-a ajuns la sfârșitul listei fără a se găsi cheia, se întoarce o structură de tip
Person, indiferent cu ce valori (comportament nedefinit).
- Complexitate în timp: O(1) best case (fără coliziuni), O(1) average case pentru număr mai mic de 1000000 de persoane, O(n) worst case (același hash pentru poate persoanele).
- Complexitate în spațiu: O(1)
Ștergerea unui HashMap
Pentru dezalocarea unui HashMap, se definește următoarea funcție:
/**
* Functia sterge hash map-ul specificat.
* @param map hash map-ul ce trebuie sters.
*/
void deleteHashMap(struct HashMap * map);
Pentru ștergerea unui HashMap se urmează următorii pași:
- Se iterează peste tot
array-ul, ștergându-se toate nodurile din toate listele.
- Se șterge memoria alocată pentru structura de tip
HashMap.
- Complexitate în timp: O(MAX_HASH)
- Complexitate în spațiu: O(1)
